java.util.concurrent.ExecutorService의 구현체로 병렬 프로그래밍을 지원
Fork Join 의미
Fork : 쓰레드를 여러개로 분할
Join : 포크해서 실행한 스레드의 결과를 취합
하나의 큰 작업을 여려개의 작업(쓰레드)으로 분할하여 실행시킨다
주요 클래스
ForkJoinPool : 등록된 태스크를 관리하는 쓰레드 풀
RecursiveTask - 실제 실행될 작업인 compute 메서드를 구현한다. 리턴값 있음
RecursiveAction - RecursiveTask와 같지만 리턴값이 없음
장점
노는 스레드가 다른 스레드의 작업을 가져와 처리하여 효율을 증대시킨다.
ForkJoin 개념도
하나의 작업을 분할(Fork)하고 분할된 하위 Task들의 작업이 완료될 때까지 기다린 후에 병합(Join)하여 최종 결과를 내는 방법이다. 위 그림을 보면 분할 정복 알고리즘과 비슷하다. 차이점은 forkjoin은 병렬로 작업이 수행된다는 점이다. 또한 Work stealing Algorithm을 사용한다는 것. 하나의 쓰레드가 작업을 다 처리하고 더 이상 할 일이 없으면 inbound-queue나 다른 쓰레드의 queue에서 할 일을 가져와서 수행하는 알고리즘이다. 그리하여 CPU 유휴시간이 줄어들게된다. 직원이 노는 꼴은 못 보는 사장 마인드 ㅋㅋ
일해라~ CPU야
성능테스트
다음은 ForkJoin을 이용한 숫자의 합계를 구하는 클래스다 RecursiveTask를 상속받아 compute() 메서드를 구현해주면된다. 리스트의 크기가 THRESHOLD 보다 작거나 같으면 바로 합계를 구하고 크면 재귀적으로 계속 이등 분할한 후 조인한다.
publicclassSumTaskextendsRecursiveTask<Long> { privatestaticfinallong serialVersionUID = 1L; privatestaticfinalint THRESHOLD = 100000; private List<Long> data; publicSumTask(List<Long> data){ this.data = data; } @Override protected Long compute(){ long sum = 0; if(data.size() <= THRESHOLD) { for(Long number : data) { sum += number; } return sum; }else { int mid = data.size() / 2; SumTask firstTask = new SumTask(data.subList(0, mid)); SumTask secondTask = new SumTask(data.subList(mid, data.size())); firstTask.fork(); return secondTask.compute() + firstTask.join(); } } }
성능을 비교하기 위해 3가지 방식의 메서드를 만든다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
//forkjoin 방식 privatestaticlongtestForkJoin(List<Long> data){ ForkJoinPool pool = ForkJoinPool.commonPool(); return pool.invoke(new SumTask(data)); } //절차적 방식 privatestaticlongtestSequential(List<Long> data){ long sum = 0; for(Long number : data) { sum += number; } return sum; }
//parallel Stream 방식 privatestaticlongtestStream(List<Long> data){ return data.parallelStream().reduce(0L, Long::sum); }
테스트 코드는 다음과 같다. 천만개의 랜덤 숫자를 더하는 연산이다
1 2 3 4 5 6 7 8 9 10 11 12
publicstaticvoidmain(String[] args){ Random random = new Random(); List<Long> randomData = random.longs(10000000, 1, 5).boxed().collect(Collectors.toList());
long startTime = System.currentTimeMillis();
long sum = testForkJoin(randomData); //long sum = testSequential(randomData); //long sum = testStream(randomData);
포크조인 방식은 threshold에 따른 성능을 알기 위해 3가지로 나눠서 실행해봤다. 각각 5번씩 실행해 평균속도를 구했다.
ForkJoin 1000
ForkJoin 10000
ForkJoin 100000
sequential
parallelStream
평균 실행 시간(ms)
37.4
31.8
38
96.8
140.6
평균적으로 ForkJoin방식이 더 빠르게 나왔다. 하지만 작업단위의 처리량과 PC의 성능에따라 오히려 ForkJoin방식이 느려질 수도 있으니 주의해서 사용해야한다. 작업을 나누는 기준과 방법을 적절히 정해야 효율적인 성능이난다.
언제 사용할까?
단순 연산 외에도 void형인 RecursiveAction를 이용해 여러가지 작업을할 수 있을거 같다. 디렉토리를 재귀적으로 탐색하는 작업이나.. 루트 웹페이지부터 링크를 따라 크롤링하는 작업 등에 사용하면 좋을거란 생각이든다. 다음은 디렉토리의 용량을 계산하는 예제이다. 루트패스로부터 시작해서 해당파일이 디렉토리인지 파일인지 판단하여 디렉토리라면 작업을 분할하여 재귀처리하고, 파일이면 크기를 리턴한다.
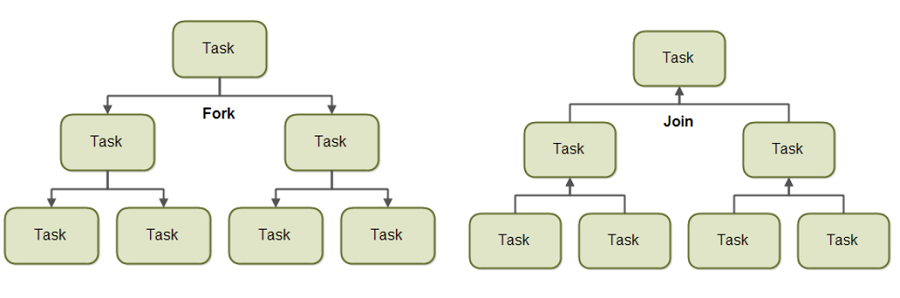 ForkJoin 개념도
ForkJoin 개념도 일해라~ CPU야
일해라~ CPU야